I Produced an Entire Commercial Audiobook Using ElevenLabs. Here’s What Nobody Tells You.
A warts-and-all production diary for The Falsehood — 31 chapters, 6 hours 19 minutes, and what the pipeline actually looked like.
Most people hear “AI audiobook” and picture a writer pasting their manuscript into a text box and pressing Generate.
That is not what happened here.
I performed every word of every chapter of The Falsehood myself, as a narrator, with full dramatic intent. ElevenLabs then transformed the voice character — from my own voice into two distinct, period-appropriate characters. The emotion, the timing, the pauses, the breath: all human. The voice character: transformed.
This distinction matters more than it might appear. It is the difference between AI-generated performance and AI-assisted production. And understanding it is the only way to make honest sense of what the technology can and cannot do.
The Book
The Falsehood is a literary historical novel published under the pen name Olivia Franklin. It is narrated in first person by a 115-year-old woman called Scarlett Hood, recounting the true story of Little Red Riding Hood — or rather, the story the folk tale erased — to her granddaughter in 1856 Missouri. The epilogue shifts narrator entirely: Olivia Franklin herself, writing in 1903.
Two distinct narrative voices. Two distinct characters. Two distinct eras. A single text-to-speech voice was never a realistic option. The voice conversion approach was the only viable path.
Why Voice Changer, Not Text-to-Speech
Text-to-speech produces clean, neutral, technically competent speech. What it does not produce is a performance.
A 115-year-old woman from 1856 Missouri has a sound, a cadence, a weight to her speech. I had to find that weight through performance first — through sitting in front of a microphone and inhabiting the character. Only then did ElevenLabs have something worth converting.
This is the crucial thing about the speech-to-speech approach: the model receives your timing, your pacing, your dramatic emphasis, and rebuilds it in another voice. It transforms the voice character; it does not improve the performance. If your base recording is flat, the conversion will be flat. The tool presupposes that you know how to narrate.
This is worth naming clearly because most “AI audiobook” content implies a shortcut that doesn’t quite exist. The shortcut is in the voice casting. Not in the performance itself.
The Two Voice Characters
Scarlett Hood is voiced using ElevenLabs’ Grandma Rachel. At 115, she speaks in Missouri vernacular — dropping her g’s, calling her mother “Momma,” carrying a density and slowness that signals both her age and the weight of what she has witnessed. Finding the right voice required listening through a range of options and testing against representative passages until the register was right. Grandma Rachel was right.
Olivia Franklin — the fictional author who frames the novel in its epilogue — is voiced using Daisy, Playful Southern Narrator. She is lighter, more educated, more formally structured in her speech. The contrast is deliberate: the listener needs to know, without being told, that the frame has shifted. Two voices do that work.
The Production Pipeline — The Real One
Here is what the pipeline actually looked like, step by step.
Step 1: Performance capture. I recorded every chapter in full as myself — raw WAV files, quiet room, condenser microphone. This is a narrator’s job. Knowing the text is not sufficient; you have to perform it, live, with the character’s voice and intention intact.
Step 2: ElevenLabs Voice Changer API. The endpoint is speech-to-speech, model eleven_multilingual_sts_v2. The API has a five-minute file cap per call. The Falsehood runs to six hours and nineteen minutes across 31 chapters. Several chapters exceed five minutes considerably. Every chapter over the cap had to be split into segments in Audacity, converted individually, and reassembled afterwards without any audible join.
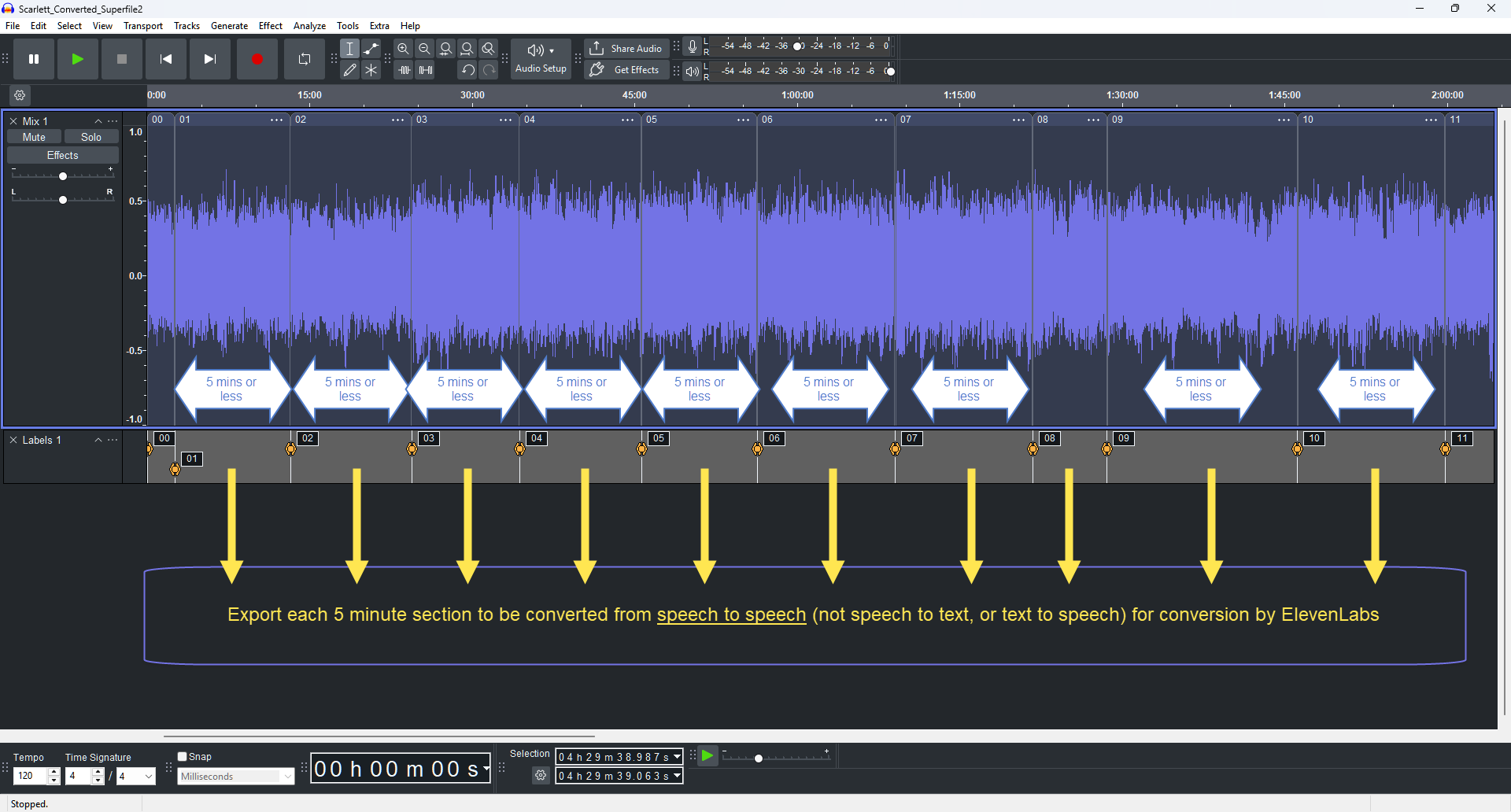 ⇱ Click to enlarge
⇱ Click to enlarge
A single chapter in Audacity, marked up with label points at every five-minute boundary. Each segment was exported separately for ElevenLabs conversion, then reassembled.
This is not a workflow the documentation walks you through. It required engineering around a real constraint. Two API keys were required to manage throughput, stored as machine-level environment variables rather than hardcoded into scripts.
Step 3: EQ and ACX treatment in Audacity. ACX — Audible’s audiobook production standard — has non-negotiable technical requirements:
Peak levels: no higher than −3dB
Noise floor: below −60dB
No clipping. No distortion.
Raw API output does not arrive ACX-compliant. Every chapter required EQ, noise reduction, compression, and normalisation passes in Audacity. This is audio engineering, not button-pressing. If you do not know your way around a DAW, this step alone will defeat you.
Step 4: Chapter splitting, naming, and tagging. ACX requires specific file naming conventions and ID3 metadata tags on every MP3. 31 chapters, each needing to be split from the processed audio, renamed to spec, and tagged with correct title, author, narrator, and chapter number metadata. I built a custom Python tool to handle this in bulk — metadata_apply.py and bulk_apply.py — and debugged it across multiple sessions. It works now. It did not work immediately.
Step 5: ACX submission. Once all 31 files passed technical review, they were submitted via ACX. One non-obvious requirement: the audiobook must be claimed against an existing Amazon ASIN. The ebook has to be published first. ACX will not accept a submission without an existing Amazon product to link to.
The Scale of the Work
Six hours and nineteen minutes sounds substantial. What it actually represents is this:
31 chapters, each requiring a minimum of seven distinct passes: performance → split if needed → API conversion → reassembly if needed → EQ → ACX treatment → split, rename, and tag → quality check. Plus the Python tooling build and debug time. Plus the ACX submission and approval wait. Plus the KDP ebook publication, which had to come first.
This was not a weekend project. I am not going to put a precise number on the total time because I was building the pipeline as I went, and the debugging time was front-loaded. If you were starting today with the pipeline already working, it would be substantially faster. It would still not be quick.
What ElevenLabs Made Possible — And What It Couldn’t Do
Being fair and specific is the only way to write about a tool honestly.
What it made possible: a solo author-narrator producing a commercially viable, Audible-quality audiobook without a recording studio or professional voice actor. Two convincing, distinct character voices from a single narrator. A production that passed ACX’s technical standards and is live on one of the world’s largest audiobook platforms.
What it couldn’t do: it couldn’t make a flat performance compelling — that was my job. It couldn’t solve the ACX compliance pipeline automatically — that required audio engineering knowledge and custom tooling. It couldn’t eliminate the five-minute cap workaround — that was a real constraint requiring real engineering. And it couldn’t substitute for the hours spent at a microphone actually narrating the book.
The technology is genuinely impressive. The marketing sometimes implies it is more self-contained than it actually is.
Hear It for Yourself
Chapter 7 — The Second Blow — runs to 12 minutes and 41 seconds. It is one of the longer chapters, and it is assembled from three separate converted segments. Each was converted independently, processed, and joined. You would not know from listening that there are joins in there. That is the point.
The Authenticity Question
I want to address this directly, because it will be asked.
I wrote every word of The Falsehood. I performed every word of The Falsehood. The voice transformation is a production choice — equivalent, in principle, to a film score being recorded in a different room from the dialogue, or a voice actor delivering a performance in an accent other than their own. The creative decisions, the emotional performance, the character interpretation: human, and entirely mine. ElevenLabs is a production tool, not a co-author.
Whether the result sounds indistinguishable from a professional studio recording is for the listener to judge. You have just had the chance to form your own view.
The Falsehood is available now on Audible.
The full audiobook. Six hours, nineteen minutes. Thirty-one chapters.

https://tinyurl.com/THE-FALSEHOOD-AUDIBLE
If You’re Thinking About Doing This
A brief practical list for authors considering a similar pipeline:
- A good condenser microphone and a quiet space. Background noise at the performance stage amplifies through every subsequent step.
- Audacity (free) and working knowledge of EQ, noise reduction, and normalisation. This is learnable, but allow time.
- ElevenLabs API access at a paid tier for speech-to-speech. Check the current pricing — it changes.
- Basic Python skills, or willingness to learn, for the metadata pipeline. Alternatively, there may be tools that handle this now. I had to build mine.
- An ebook already published on Amazon. ACX requires this before submission.
- Time. More than you think.
The pipeline exists. It is not frictionless. The result is genuinely yours.