The fAIt Accompli
Is Agent Smith’s Future Really “Inevitable”?
The third in a series of six articles exploring evaluation, measurement, and why we keep getting it wrong.
 Most organisations believe they are adopting AI.
Most organisations believe they are adopting AI.
In reality, they are accumulating something else: assimilation debt.
Every new tool is being deployed faster than people can genuinely understand it. Adoption dashboards look healthy, training completion rates are improving, and usage is rising. But beneath those encouraging metrics the gap between what is being used and what is actually understood is quietly widening.
That gap may turn out to be the most important measurement problem in AI transformation.
In the first Matrix film, Agent Smith leans across and explains to Morpheus that he has spent some time attempting to classify the human species, and his conclusion is a troubling one.
I’d like to share a revelation I’ve had during my time here. It came to me when I tried to classify your species. I realized that you’re not actually mammals. Every mammal on this planet instinctively develops a natural equilibrium with their surrounding environment, but you humans do not. You move to another area, and you multiply, and you multiply, until every natural resource is consumed. The only way you can survive is to spread to another area. There is another organism on this planet that follows the same pattern. Do you know what it is? A virus. Human beings are a disease, a cancer of this planet. You are a plague, and we are the cure.
It is one of cinema’s more unsettling speeches, and it has quietly colonised our collective imagination of what artificial intelligence might eventually conclude about us. The Skynet scenario. The machine uprising. The moment AI decides that humanity, on balance, is more problem than asset.
I want to suggest that we have been afraid of entirely the wrong thing.
In the three premises that follow, I want to do three things. First, I want to examine what AI transformation actually looks like on the ground, as opposed to what the cultural narrative has led most organisations to expect. Second, I want to apply a measurement principle that practitioners in this field should already know, but that most organisations are currently violating at considerable scale. And third, I want to explain why the structural conditions of AI deployment have made this measurement failure almost impossible to avoid. Together, these three arguments lead to a conclusion that I believe should concern anyone carrying responsibility for learning strategy in their organisation.
Premise A: The Fear We Were Given Is Not the Fear We Need
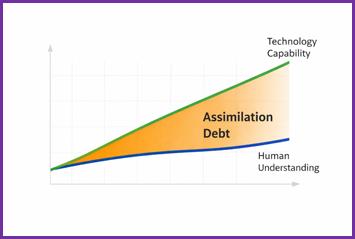 The popular conception of AI risk is Agent Smith’s: dramatic, confrontational, and existential. Machines develop intent. Humans are displaced or eliminated.
The popular conception of AI risk is Agent Smith’s: dramatic, confrontational, and existential. Machines develop intent. Humans are displaced or eliminated.
The appropriate response, in this telling, is to build the off switch before it is too late, or at least to hold an anxious conference about it.
The problem is that this version of AI inevitability requires artificial intelligence to develop agency, hostility, and something very like a grievance, none of which are on any credible near-term technical horizon. More importantly, the Skynet story casts humans as passive victims of an external force, which conveniently spares us the discomfort of examining what we are actually doing to ourselves.
What is actually unfolding is considerably less dramatic and, in some ways, considerably harder to resist precisely because it generates so little alarm. It is not conquest but mediation. More and more knowledge work is beginning to flow through artificial intelligence platforms, not because anyone is being coerced, but because the alternative is becoming progressively expensive. Questions flow through platforms. Research flows through platforms. Increasingly, the framing of problems and the structuring of arguments flow through platforms too. This is historically consistent with how transformative technologies move: from novelty to infrastructure, from individual choice to institutional assumption. AI is the next layer of this familiar pattern, and very likely the most consequential one, because it extends the logic into cognition itself.
The language accompanying this shift has been carefully chosen. We are not told that adoption is compulsory. We are told, with apparent generosity, that we should not get left behind. The coercive element is implicit rather than stated, which makes it considerably more difficult to examine critically.
But the deeper problem for organisations is not adoption pressure. It is the gap between adoption and what I would call assimilation: the slower, internal process by which people develop genuine intuition about a tool, learn its failure modes through experience, and build the kind of embedded judgement that tells them when not to use it as much as when to use it. Adoption is behavioural and relatively fast. Assimilation is cognitive and inherently slow.
Consider how organisations absorbed the mobile telephone.
 The progression from the heavy handsets of the late 1980s to the smartphone took roughly a decade, and each stage arrived with sufficient breathing space to become familiar before the next appeared. Texting. Then cameras. Then music. Then a pocket computer that Apple chose to frame not as what it actually was, but as a familiar telephone that could do some of what you already enjoyed on your personal computer. The radical was smuggled in beneath the familiar, and the decade-long pacing made genuine assimilation possible at each stage.
The progression from the heavy handsets of the late 1980s to the smartphone took roughly a decade, and each stage arrived with sufficient breathing space to become familiar before the next appeared. Texting. Then cameras. Then music. Then a pocket computer that Apple chose to frame not as what it actually was, but as a familiar telephone that could do some of what you already enjoyed on your personal computer. The radical was smuggled in beneath the familiar, and the decade-long pacing made genuine assimilation possible at each stage.
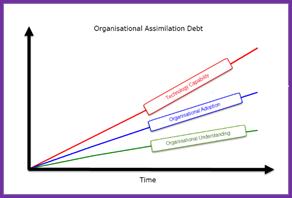 Artificial intelligence is not giving organisations that pacing. Significant capability updates now arrive every two to three weeks. The tool your teams had adequately understood last month is not quite the same tool today. Organisations are, collectively, accumulating what might reasonably be called assimilation debt: a growing and compounding gap between what is being used and what is genuinely understood. We are, structurally, in a state of permanent early adoption, with all the shallow confidence, inconsistent judgement, and unexamined assumptions that permanent early adoption produces.
Artificial intelligence is not giving organisations that pacing. Significant capability updates now arrive every two to three weeks. The tool your teams had adequately understood last month is not quite the same tool today. Organisations are, collectively, accumulating what might reasonably be called assimilation debt: a growing and compounding gap between what is being used and what is genuinely understood. We are, structurally, in a state of permanent early adoption, with all the shallow confidence, inconsistent judgement, and unexamined assumptions that permanent early adoption produces.
Premise B: We Are Measuring the Wrong Things, and Goodhart Saw This Coming
 For those of you who did not read my earlier article, let me precis it for you.
For those of you who did not read my earlier article, let me precis it for you.
In the 1970s, the economist Charles Goodhart observed something troubling about monetary policy: the moment a government started targeting a specific economic indicator, the relationship between that indicator and the underlying reality it was supposed to represent began to break down. The act of targeting the measure changed the behaviour the measure was intended to capture.
 Marilyn Strathern later compressed this insight into a formulation that deserves considerably wider circulation than it receives:
Marilyn Strathern later compressed this insight into a formulation that deserves considerably wider circulation than it receives:
“When a measure becomes a target, it ceases to be a good measure.”
The examples are almost instructive in their absurdity.
The British colonial administration in Delhi offered a bounty per dead cobra to reduce the city’s snake population. Enterprising locals began breeding cobras to collect the reward.  When the scheme was cancelled and the cobras became worthless, the breeders released them, and the population ended up larger than before.
When the scheme was cancelled and the cobras became worthless, the breeders released them, and the population ended up larger than before.
 Soviet factory managers given production targets measured in weight manufactured enormous, unusable nails; when the target was switched to the number of nails, they produced vast quantities of tiny, unusable tacks.
Soviet factory managers given production targets measured in weight manufactured enormous, unusable nails; when the target was switched to the number of nails, they produced vast quantities of tiny, unusable tacks.
 Wells Fargo staff, given aggressive targets for new account openings, opened millions of fraudulent accounts in customers’ names without their knowledge or consent. In each case, the metric was consistently met. The actual purpose was being systematically destroyed. Nobody set out to be dishonest or irrational. They were responding entirely reasonably to the incentive structure they had been given. The mistake lay with whoever designed the measurement system and stopped thinking about what it was actually for.
Wells Fargo staff, given aggressive targets for new account openings, opened millions of fraudulent accounts in customers’ names without their knowledge or consent. In each case, the metric was consistently met. The actual purpose was being systematically destroyed. Nobody set out to be dishonest or irrational. They were responding entirely reasonably to the incentive structure they had been given. The mistake lay with whoever designed the measurement system and stopped thinking about what it was actually for.
Now consider how most organisations are currently measuring their AI transformation.
 They are counting: licences purchased, training modules completed, tools deployed, and sessions logged.
They are counting: licences purchased, training modules completed, tools deployed, and sessions logged.
These are adoption metrics. They are measurable, they are reportable to boards and leadership teams, and they bear about as much relationship to genuine organisational transformation as the number of cobras submitted to the Delhi authorities bore to the safety of the city’s streets.
 Those of us who have spent careers in Learning and Development should find this failure painfully familiar. For more than fifty years, the dominant framework for Kirkpatrick training evaluation has been the: reaction (did people find the training satisfactory?), learning (did they acquire the knowledge?), behaviour (did they change how they actually work?), and results (did the organisation benefit in measurable terms?).
Those of us who have spent careers in Learning and Development should find this failure painfully familiar. For more than fifty years, the dominant framework for Kirkpatrick training evaluation has been the: reaction (did people find the training satisfactory?), learning (did they acquire the knowledge?), behaviour (did they change how they actually work?), and results (did the organisation benefit in measurable terms?).
The model has an elegant simplicity that obscures a fundamental structural problem: these are not levels in any meaningful hierarchy. They are entirely different dimensions requiring completely different measurement approaches, and the higher you climb, the more difficult and resource-intensive measurement becomes.
The consequence, under Goodhart’s Law, is entirely predictable. Organisations measure what is easy. Reaction scores are collected automatically at the end of a session. Knowledge assessments are built into the delivery platform. Behaviour change requires manager observation over time, which is labour-intensive, subjective, and inconsistent, so most organisations skip it. Business results require attribution that is genuinely difficult to establish with rigour, so either this step is skipped entirely or organisations produce ROI figures that no serious analyst believes. The measurement becomes the target.
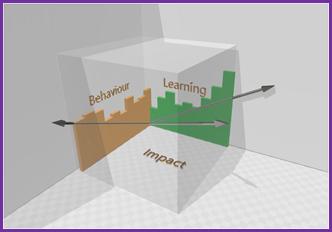 The TriAxis Model that I introduced in the earlier articles in this series attempts to address this by separating the dimensions of evaluation entirely and assessing them independently: skill progression (objective and demonstrable), experience quality (subjective but deliberately lightweight), and business connection (honest about what can and cannot be attributed). These are treated as parallel questions rather than sequential hurdles. The intent is to make it structurally harder to optimise for a single proxy at the expense of the complete picture, and to make the Goodhart trap visible rather than allowing it to hide behind an apparently coherent framework.
The TriAxis Model that I introduced in the earlier articles in this series attempts to address this by separating the dimensions of evaluation entirely and assessing them independently: skill progression (objective and demonstrable), experience quality (subjective but deliberately lightweight), and business connection (honest about what can and cannot be attributed). These are treated as parallel questions rather than sequential hurdles. The intent is to make it structurally harder to optimise for a single proxy at the expense of the complete picture, and to make the Goodhart trap visible rather than allowing it to hide behind an apparently coherent framework.
The same discipline is needed, with some urgency, for how organisations are currently evaluating their AI adoption.
Premise C: The Trap Was Designed In
If assimilation debt describes the condition of organisations struggling to absorb a technology that changes faster than they can internalise it, and if Goodhart’s Law explains why the measurement systems most organisations are using are structurally incapable of detecting the problem, there is a third element worth naming: the conditions of AI deployment have been designed in ways that make honest evaluation very difficult to sustain, and this is not entirely accidental.
Consider the position of a mid-sized organisation at this particular moment. Competitors are announcing AI initiatives. Boards are asking questions. Technology vendors are offering favourable terms for early commitment.
 Microsoft, to take the most widely visible example, has branded its AI offerings under the single name Copilot, which creates the impression of a coherent, unified assistant integrated smoothly across an organisation’s existing workflows. The reality is considerably more provisional. Copilot is a label applied to several distinct specialist models deployed across different products, each with different capabilities, different limitations, and an architecture that its creators are still actively developing. The branding implies completeness and maturity. The underlying product is still being built.
Microsoft, to take the most widely visible example, has branded its AI offerings under the single name Copilot, which creates the impression of a coherent, unified assistant integrated smoothly across an organisation’s existing workflows. The reality is considerably more provisional. Copilot is a label applied to several distinct specialist models deployed across different products, each with different capabilities, different limitations, and an architecture that its creators are still actively developing. The branding implies completeness and maturity. The underlying product is still being built.
Organisations are being asked to make large-scale, often irreversible integration decisions about a technology that has not been stable long enough to evaluate properly. Genuine due diligence requires the subject of the diligence to remain sufficiently stable to be assessed; when the technology changes every few weeks, the evaluation can never complete. Organisations face an uncomfortable choice between proceeding without adequate evidence, or deferring commitment while competitors appear to move ahead.
This is not a conspiracy. It is economic gravity. The organisations building these platforms benefit from the speed of adoption and have every rational incentive to lower the barriers to entry and create a sense of urgency around commitment. The path of least resistance has been carefully landscaped, and the landscape has been designed with particular preferences in mind. Those preferences do not necessarily align with the interests of the organisations, or the people, being asked to move quickly.
The result, in measurement terms, is an environment almost perfectly calibrated to produce Goodhart’s failure at scale. The adoption metrics look encouraging. The training completion rates are improving. The tools are being used. And somewhere beneath all of this, assimilation debt is compounding quietly, behaviour change is not being measured because it is difficult and inconvenient, and the question of whether any of this is producing results at the level Kirkpatrick would actually care about remains, for most organisations, politely unasked.
Where Does This Leave Us?
 Panic is not the answer. Neither is uncritical enthusiasm. Both are, beneath their very different emotional temperatures, structurally similar responses: each assumes the organisation has limited meaningful agency, and each is, in its own way, a form of surrender to a narrative of inevitability.
Panic is not the answer. Neither is uncritical enthusiasm. Both are, beneath their very different emotional temperatures, structurally similar responses: each assumes the organisation has limited meaningful agency, and each is, in its own way, a form of surrender to a narrative of inevitability.
Panic says the future is already decided against us. Enthusiasm says it is already decided in our favour. In both cases, the measurement problems described above continue undisturbed.
The more useful response is what I would call discernment: the willingness to hold two things simultaneously, namely that the transformation is real and substantial, and that the outcome is not yet written. For L&D practitioners and AI strategy consultants alike, this means something specific and actionable. It means insisting on honest measurement at a moment when the incentive structures are pointing comprehensively in the opposite direction. It means asking Kirkpatrick’s harder questions, whether behaviour has genuinely changed and whether that change is producing results worth the investment, even when those questions are uncomfortable and the answers are inconclusive. It means applying the three-dimensional discipline of the TriAxis approach to AI adoption itself: separating the question of whether people are using AI from the question of whether they are using it well, and separating both from the question of whether it is producing outcomes the organisation can properly attribute.
It means, above all, refusing to mistake the adoption dashboard for the reality it is supposed to represent.
Agent Smith was wrong about humans. He was wrong about the direction of the threat and wrong about the nature of the cure. But he was not wrong that patterns have momentum, or that the organisms moving through a system do not always understand the system they are moving through. The question for organisations right now is whether they are passengers in the pattern of AI adoption or whether they are, with clear eyes and honest instruments, participants in shaping where it actually leads.
 The fAIt accompli is real enough. But it is not yet written. Agent Smith believed inevitability was the natural conclusion of flawed systems. As Sarah and John Connor put it: the future is not written. There is no fate but what we make. The difference between those two things is, in the end, a question of whether we are still asking what our numbers are actually for.
The fAIt accompli is real enough. But it is not yet written. Agent Smith believed inevitability was the natural conclusion of flawed systems. As Sarah and John Connor put it: the future is not written. There is no fate but what we make. The difference between those two things is, in the end, a question of whether we are still asking what our numbers are actually for.
Coming Next
The sharp-eyed among you will rightly criticise the simplification of my TriAxis visualisation above. When I first modelled the space in three dimensions it became obvious to me that there is a huge missing element, which will be discussed in Article 4.
I’m currently considering titles including: Impact Drift, Vector Drift, Outcome Drift, Intent–Impact Divergence.
Stay tuned.